Protect what is priceless
Dive in Faraday’s Vulnerability Management Platform
Protect what is priceless
Dive in Faraday’s Vulnerability Management Platform
Get a Free TrialBook a Demo
Change the way you do cybersecurity
Faraday provides a smarter way for Large Enterprises, MSSPs, and Application Security Teams to get more from their existing security ecosystem.
Some of the companies that trust us














150+
Normalize and Integrate
security tools
Get vulnerability data from more than 150 integrations.
7x
Faster vulnerability
managing and prioritization
Built around collaboration, manage, tag, prioritize with ease.
10x
Automate with Agents
and Workflows
Automate vulnerability response to remediate faster.
A 360° flexible overview
Optimize your security posture by drastically reducing the time spent on executing, managing, and prioritizing


Some of the leading security scanners we support




Some of the ticketing tools we integrate with
Avoid repeating single tasks
Built with an automation
framework in mind
Workflows
Trigger any action with custom events built to avoid repetitive tasks.
Agents
Integrate scanners automatically into your workflow, scan, ingest and normalize data easier than before.
Seamless Deduplication
Faraday automatically identifies and merges duplicated issues coming from multiple tools.
Make vulnerability management faster, smarter, and more efficient
Make vulnerability management faster,
smarter, and more efficient
Faraday was designed to ease every step of your job. Here’s how:
Read our latest posts

Enhanced Vulnerability Management Guide Using Open-Source Tools
In the dynamic world of IT security, proactive vulnerability management is key. This comprehensive guide introduces…
0 Comments4 Minutes
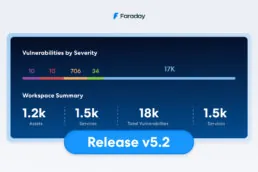
Release v5.2.0
Welcome to another great version of Faraday. This time, we introduce new methods to make your workflow even more…
0 Comments3 Minutes

Good practices in Cybersecurity – Part 2
Nowadays, we can distinguish various branches within a security team Red Teams, Blue Teams, Purple Teams & Bug……
0 Comments6 Minutes